Quick Links
Trigger a Crawl and View Results | Site Summary Tab | Pages Tab | PDF Tab | FAQ
How to Trigger a Crawl and View Results
Step 1: Make Sure the Feature is Enabled
Crawling isn't available by default for standard Checker accounts. To get started, you'll need to have this feature enabled on your organisation. Your Customer Success Manager can guide you through the available options and help get it activated.
Step 2: Add a New Domain to Trigger a Crawl
Once enabled, a crawl is automatically triggered when you add a new domain:
-
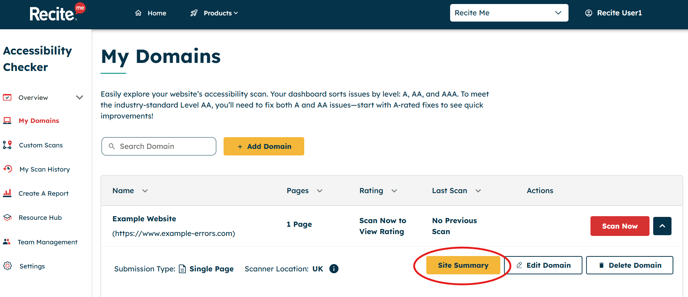
Go to ‘My Domains’
-
Click ‘Add Domain’ → ‘Scan Single Page’
-
Enter your domain URL
-
Give it a name for easy reference
-
Click ‘Preview’, then hit ‘Save’
⚡ You do not need to manually start a scan—the crawl begins as soon as the domain is saved.
Step 3: View Crawl Status & Results
To check crawl progress and results:
-
Go to ‘My Domains’
-
Find your domain
-
Click the arrow next to ‘Scan Now’
-
Select ‘Site Summary’
You’ll now see a full overview of the crawl results.
Site Summary Tab
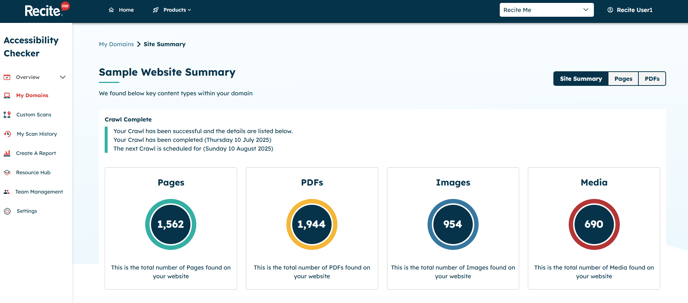
The Site Summary is your command center for crawl results. It displays the top-level findings across all detected content on your website, including:
-
📄 Web pages
-
📑 PDFs
-
🖼️ Images
- For images we detect any <img> HTML elements within a page for the following file extensions JPG, JPEG, PNG, GIF, SVG, WebP.
-
🎥 Media files
- For media we detect any <video> HTML elements within a page, we do not detect embedded video from third party platforms such as YouTube or Vimeo.
On the Site Summary tab, you’ll see a crawl status indicator that shows the current progress of your website scan. The status can be in one of the following three states:
- ✅ Crawl Complete
Your Crawl has been successful and the details are listed below.
Your Crawl has been completed (DATE APPEARS HERE)
The next Crawl is scheduled for (DATE APPEARS HERE) - 🟠 Crawling in Progress
Your domain is currently being Crawled for content.
The information below is shown in real time - 🔴 Issue with Crawl
Unfortunately, we have been unable to complete the Crawl of your domain.
⏱️ Crawl Timing & Recurrence
The time it takes to complete a crawl depends on the size and complexity of your domain. Crawling and analysis may take a short while, so we recommend continuing with other tasks within Checker and returning later to review your results.
Once a crawl is complete, you'll see the completion date displayed in the Site Summary. Your domain will then be automatically re-crawled every 30 days to detect any new or removed content.
⚠️ Crawl Issues
If you see a status labelled ‘Issue with Crawl’, it means we were unable to successfully crawl your domain. This may be due to restrictions set by your website hosting provider.
In this case, please contact your Customer Success Manager. We may need to supply a list of IP addresses to be whitelisted in order to enable successful crawling.
.
Pages Tab
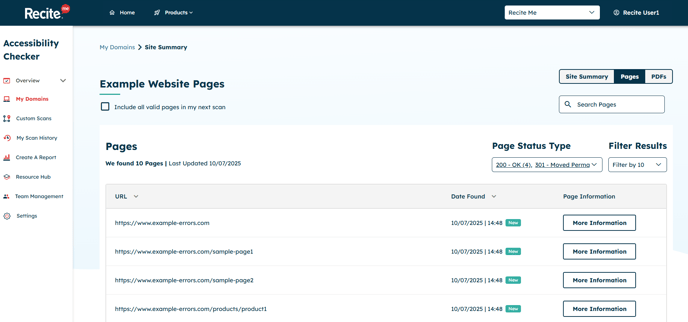
The Pages tab shows a complete list of all webpages detected during the crawl, including both HTTP and HTTPS pages for the domain you've added.
For each detected page, you’ll see:
-
🟢 Page Status Type – e.g., 200 OK, 404 Not Found
-
🔗 Parent Page URL – the source page where the link was discovered
-
📅 Date Found – when the page was first identified during the crawl
🔍 Filtering & Search Features
-
Page Status Type Filter: Quickly identify issues like 404 – Not Found, which indicate broken links or removed content.
-
Search by Folder Structure: Use the search bar to filter by specific URL paths or folders. This helps you understand how many pages exist within different sections of your website.
PDFs Tab
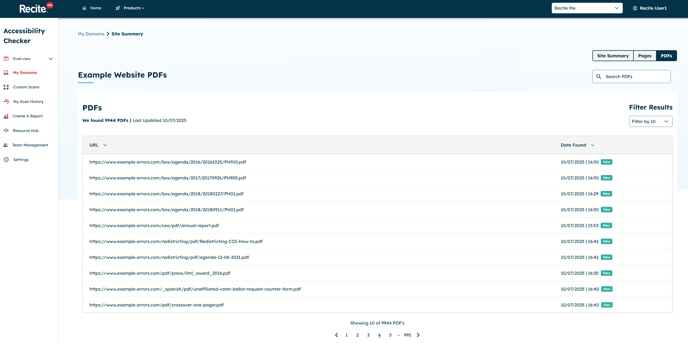
The PDF section displays all PDF files detected within your website’s pages. This includes:
-
📂 PDFs hosted directly on your main domain
-
🌐 PDFs hosted on external domains but linked from your site
🔍 Smart Search & Filtering
Use the search bar to quickly find specific PDF files by name or to filter by folder structure, making it easy to locate documents in different areas of your site.
This view helps you ensure that all documents are discoverable—no matter where they're hosted.
FAQ
Is the crawler feature enabled in my account by default?
By default, the crawler is not enabled in your account. To activate it, please contact your Customer Success Manager to discuss your options.
If I add new pages and PDFs to my site will the crawler find these?
The crawler is set to automatically re-crawl your domain every 30 days. Any new pages or PDFs found since the last crawl will be added to your results.
Will it crawl subdomains of my website?
Not by default - if you have a subdomain like shop.mydomain.com but only added www.mydomain.com, the crawl won’t include the shop subdomain. To include it, you’ll need to add it as a separate domain.
What are the most common page status types I will see?
✅ 200 – OK
What it means: The page loaded just fine. Everything is working.
🚫 404 – Not Found
What it means: The page doesn’t exist. It might have been moved or deleted.
🔒 403 – Forbidden
What it means: You’re not allowed to see this page. Maybe you need to log in.
🔄 301 – Moved Permanently
What it means: This page has a new address. You’re being sent there automatically.
🛑 500 – Server Error
What it means: Something is broken on the website’s side. It’s not your fault.